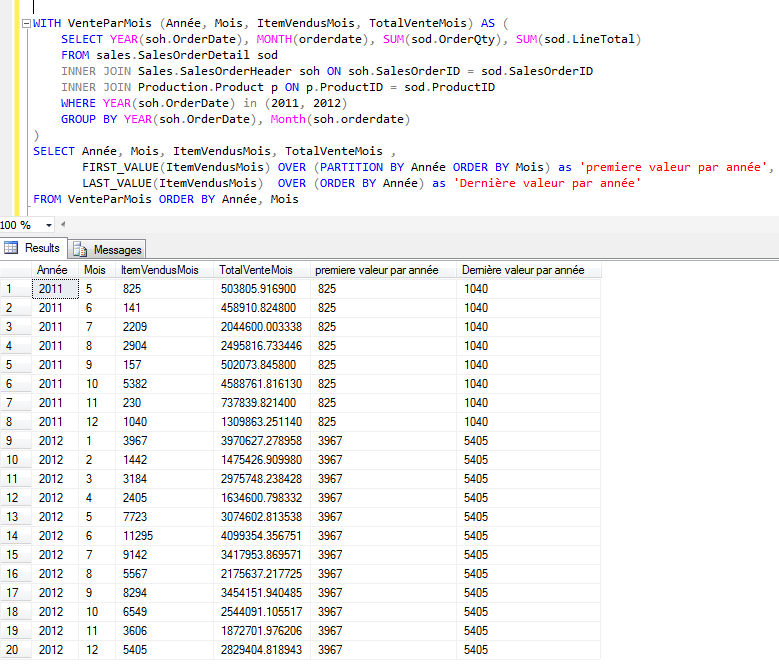
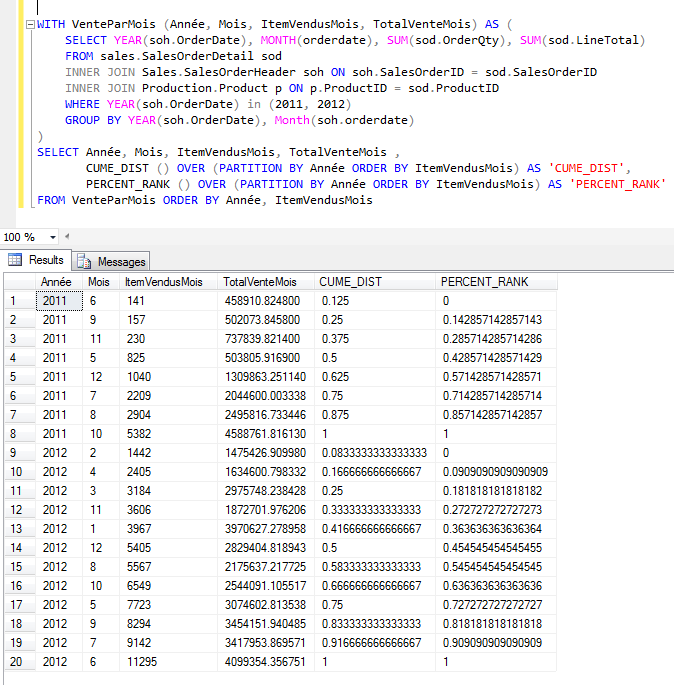
Lorsqu'on veut implémenter une
certaine logique qui implique, notamment, de faire la multiplication
sur un ensemble d'enregistrement, on se retrouve vite pris au
dépourvu sans l'aide d'une fonction d'agrégation comme la fonction
SUM qui nous permettrait de faire la multiplication d'un champs sur
un ensemble d'enregistrements.
Qu'à cela ne tiennent, il existe des
techniques pour surmonter ce problème.
Technique des logarithmes
La première façon de faire est
d'utiliser les propriétés logarithmiques. Les deux propriétés qui
nous intéressent sont les suivantes :
- log (a * b) = log (a) + log (b)
- exp(log(a)) = a

Avec la première propriété, on peut
transformer la multiplication en sommation, et avec la deuxième
propriété, on peut retrouver le résultat de la multiplication.
Pour démontrer cette solution, prenons
par exemple un jeu de données comprenant les valeurs de 1 à 5.

Pour obtenir le résultat de la
multiplication en utilisant les propriétés logarithmiques, il
suffit de faire la requête suivante

Cette méthode est simple et efficace,
mais elle a l'inconvénient d'ajouter un facteur d'erreur dans le
résultat. Même si on multiplie des valeurs de type entière, le
fait qu'on utilise la fonction LOG et que celui-ci nous retourne un
type FLOAT et qu'ensuite, on utilise cette valeur de type FLOAT en
paramètre à la fonction EXP qui nous retourne aussi un type FLOAT
fera en sorte qu'il existe la possibilité d'arrondissement et ainsi,
fausser le résultat.
Technique de la récursivité
Une autre technique consiste à
utiliser les CTE et la récursivité pour multiplier les différentes
valeurs.
Prenons encore notre ensemble de
données avec les valeurs de 1 à 5. Nous construisons ensuite un CTE
qui permet de calculer la multiplication entre le chiffre courant et
la valeur, déjà multipliée, précédente.

Cette méthode est un peu moins simple
que la première, mais elle a l'avantage de ne pas introduire un
facteur d'erreur d'arrondissement pour les données de type entière.
Il faut néamoin s'assurer de prendre la dernière valeur calcul,
d'où le "SELECT TOP 1 ..... ORDER BY id DESC".
Par contre, elle introduit une nouvelle
limitation, soit celle du nombre maximal de récursion dans la
requête. Par défaut, le nombre maximal est de 100.

Si le nombre de récursion se doit
d'être plus élevé, on peut soit utiliser l'option MAXRECURSION ou
utiliser la technique "diviser pour régner", mais peu
importe la technique choisi, il faudrait aussi tenir compte du type
de donnée et s'assurer que le type soit capable de contenir la
valeur de retour et ainsi éviter les débordements.
Pour l'option MAXRECURSION, il suffit
simplement d'écrire l'option à la fin de l'instruction FROM.
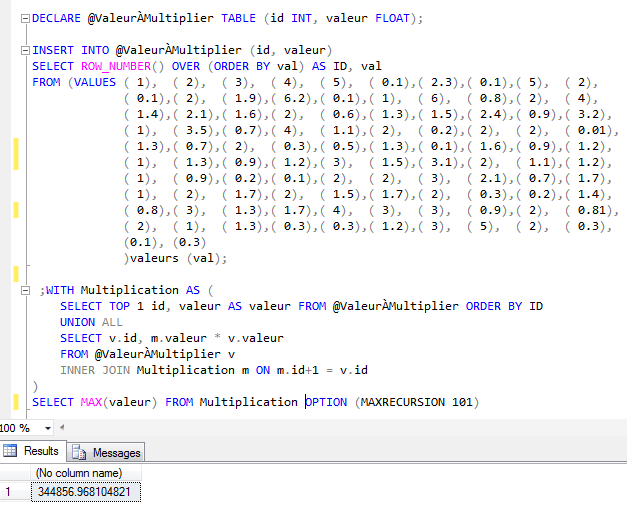
Il est très rare qu'on sache à
l'avance le nombre d'enregistrements qu'on devra multiplier ensemble.
Pour contrer cette problématique, puisque la multiplication est
associative (on peut interchanger les positions sans problèmes), on
peut séparer notre ensemble de valeur à multiplier en différentes
parties qui seront multipliées entre eux pour ensuite multiplier les
résultats et ainsi former notre résultat final.
Pour diviser notre ensemble en
sous-ensemble, nous effectuons une division entière de l'id unique
par le nombre maximal de valeur qu'on veut par couche jusqu'à un
maximum de 100, soit la limite supérieur de récursion. Dans notre
exemple avec 102 valeurs, nous divisons notre ensemble par couche de
5 valeurs pour avoir plus d'une partition.

Une fois nos partition créées, il
suffit de boucler dans notre second ensemble de données pour
multiplier l'ensemble des partitions et obtenir notre résultat final