Dans la première partie,
nous avons vu, à l'aide de la fonction ROW_NUMBER, comment les
clauses OVER, PARTITION BY et ORDER BY peuvent découper les jeux de
données pour permettre le calcul de valeur sur une partie des
données.Dans ce post, nous allons voir comment ces clauses peuvent
impacter les fonctions d'aggréations sans l'utilisation d'une clause
GROUP BY.
Les fonctions
d'aggrégations (MIN, MAX, SUM, COUNT, …) peuvent être utilisé
avec les clauses de partitionnement de données, mais il faudrait
faire attention car elle ne fonctionnent pas de la même façon.
Sans la clause OVER, les
fonctions d'aggrégation ont besoin de la clause GROUP BY pour
pouvoir effectuer
les calculs sur un sous-ensemble de données. Essayer d'utiliser une
fonction d'aggrégation sans clause GROUP BY provoquera immédiatement
une erreur de syntaxe.
En utilisant la clause
OVER, nous pouvons omettre la clause GROUP BY, mais, puisque les
données ne seront pas regroupées, nous devrons porter une attention
sur le résultat. Par exemple, avec une clause GROUP BY, nous avons
ce résultat

En utilisant une clause
OVER et en supprimant la clause GROUP BY, on peut obtenir la même
valeur dans la colonne « Nombre », mais comme les données
du résultat ne sont pas regroupées sur le champ ProductID, on aura
des duplicats.

Si c'est ce que l'on veut,
c'est bien, sinon on peut ajouter une clause DISTINCT pour obtenir le
même résultat.

Mais dans quels cas on
voudrait avoir ce comportement? Puisque le SELECT est évalué avant
la clause GROUP BY, en utilisant la clause OVER nous pouvons
spécifier une granularité différente de la clause GROUP BY et
ainsi avoir une plus grande flexibilité. Comme par exemple, nous
voudrions ajouter les informations suivantes, le nombre d'item vendu
d'un produit dans l'ensemble de notre jeu de données ainsi que le
nombre de produit différents vendu par vente.

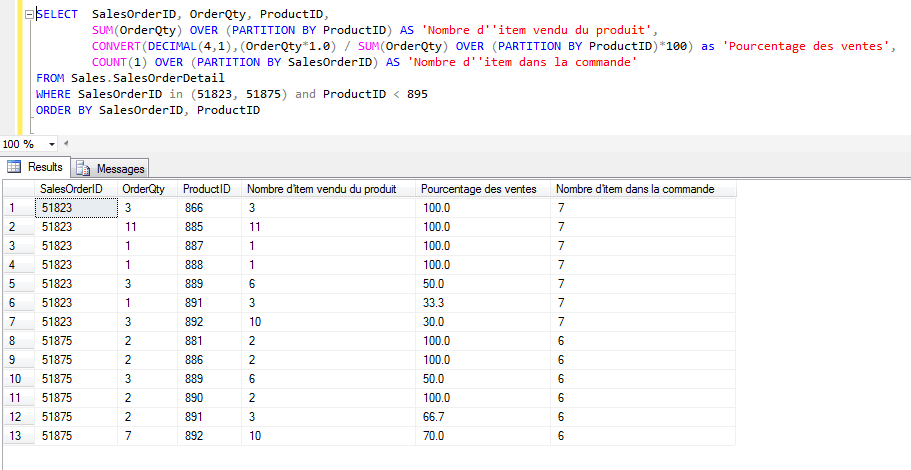
Comme on peut le voir, le
nombre d'item vendu du produit fait la somme des items vendus sans
égard à la facture, tandis que nombre d'item dans la commande
comptabilise seulement les différents produits dans une commande,
sans égard aux produits.
En ayant cette
flexibilité, nous pouvons effectuer des calculs plus simplement que
de les calculer dans des tables temporaires ou sous-requêtes pour
ensuite les joindre à notre ensemble de données.
Un autre exemple de la
puissance et de la flexibilité du partitionnement de données est qu'on
peut calculer le ratio d'une donnée par rapport à
l'ensemble. Par exemple, si on veut calculer le pourcentage des
produits vendus par ventes, on peut facilement diviser la quantité
vendu d'une vente par la quantité total vendues.
Références :













