Peu connues, SQL Server offre quelques
fonctions analytiques qui permettent d'obtenir plus d'informations sur
l'ensemble de données qui est traité. De les huit différentes
fonctions analytiques que SQL Server nous fournis, on peut les diviser en
deux catégories: les fonctions analytiques de positionnement et les
fonctions analytiques sur la distribution des valeurs.
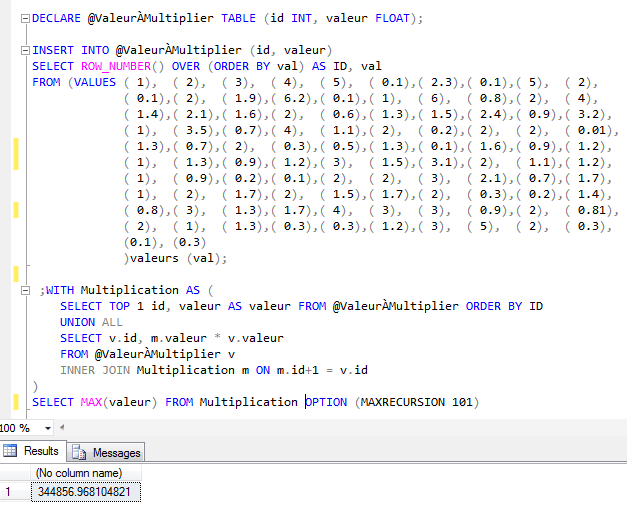
Pour démontrer chacune des fonctions,
je vais prendre le même ensemble de données, soit le total des items vendus par mois ainsi que le total des ventes mensuel de la base de données AdventureWorks. Pour
restreindre le jeu de données et pour ne pas être submergé de
données, je vais limiter les ventes qu'aux années 2011 et 2012. La
requête utilisée pour nous donner le jeu de données est la suivante.
Fonctions analytiques de positionnement
SQL Server offre 4 fonctions analytique
pour connaitre les différentes valeurs des enregistrements
précédents ou suivants. L
FIRST_VALUE
Comme son nom l'indique, cette fonction
nous donne la valeur du premier enregistrement selon l'ordre spécifié
ainsi que selon le partitionnement des données. Cette valeur n'est
pas nécessairement la première valeur retournée dans le résultat,
mais bien la première valeur selon la clause OVER qui est spécifié.
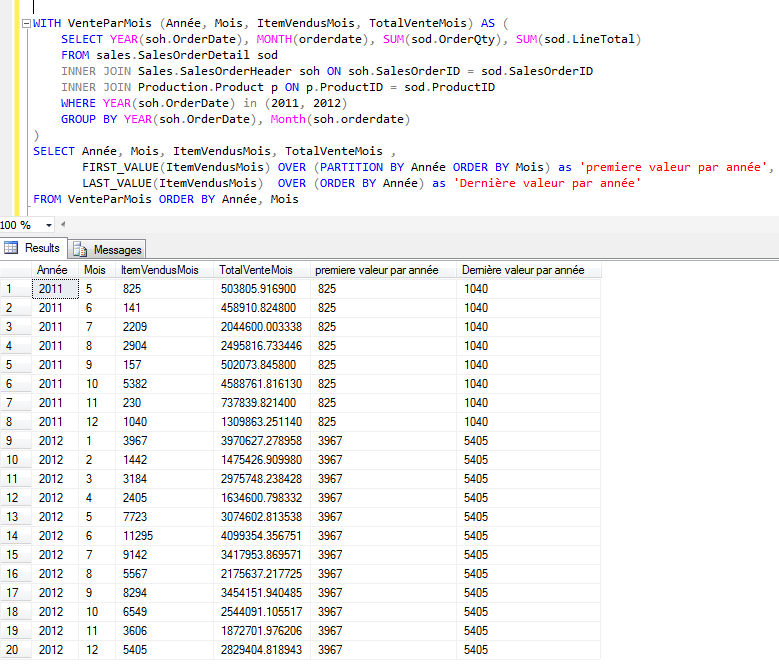
Par exemple, on veut avoir la première valeur des items vendu par
mois, ordonnancé par mois
Comme on a ordonnancé par mois
seulement et que le plus petit mois est 1, on a donc cette valeur,
soit 3967. Par contre, si on veut la première valeur par année, il
faut partitionner nos données par année.
En partitionnant nos données, la
première valeur est calculée pour chaque partitionnement en prenant
la valeur associé au mois le plus petit, soit le 5ième mois pour
l'année 2011 et pour le premier mois de 2012.
LAG
La fonction LAG nous permet de
connaitre les valeurs précédentes à l'enregistrement courant. Par
défaut, la fonction LAG retourne la valeur précédente, mais on
peut aussi lui indiquer la n-ième valeur que nous souhaitons
connaitre. Lorsque la valeur demandée n'existe pas, la valeur NULL
est retournée.
Ainsi, dans notre exemple, on peut
connaitre le nombre d'items vendus pour les mois précédents.
LEAD
De la même façon que la fonction LAG,
la fonction LEAD permet de connaitre les valeurs suivantes à
l'enregistrement courant. Ainsi, dans notre exemple, on peut
connaitre le nombre d'items vendus pour les mois suivants.
LAST_VALUE
La dernière fonction analytique de
positionnement est la fonction LAST_VALUE qui est sensiblement comme
la fonction FIRST_VALUE, mais qui comporte une petite spécifité qui
peut en mystifier plus d'un.
On se rappel que, lorsqu'on a calculé
la FIRST_VALUE plus tôt, nous avons partionné nos données par
année pour avoir une valeur correspondant à la première valeur par
année.
Sans partitionnement
Avec partitionnement
Pour la fonction LAST_VALUE, c'est
différent. Voyons ce qu'il arrive lorsqu'on utilise la même clause
OVER que pour FIRST_VALUE
On remarque que pour FIRST_VALUE, on a
bien la bonne valeur, mais pour LAST_VALUE, on a la même valeur que
pour ItemVendusMois. Et cette valeur peut nous mystifier un peu plus
si nous omettons la clause PARTITION BY où il semble prendre
n'importe quelle valeur.
Dans les faits, LAST_VALUE calcule la
dernière valeur en fonction de la clause PARTITION BY ainsi que pour
chaque valeur distinctes de la clause ORDER BY. Dans notre exemple,
comme on veut la dernière valeur de l'année, on doit ordonnancer
par année, ce qui nous donnera la bonne valeur.
On peut valider ceci en prenant des
valeurs arbitraires pour y appliquer la fonction LAST_VALUE.
Par exemple, dans la requête suivante,
on se créer des couples de données (A,B) pour en calculer la
dernière valeur. On remarque que dans la dernière colonne
(LAST_VALUE ORDER BY A), on a la valeur B qui est associé à la
dernière occurence de la valeur A (les enregistrements bleutées).
À l'inverse, lorsqu'on trie par B pour
avoir la dernière valeur de A, on a le même phénomène. Pour
chaque valeur distinct de B, on a la valeur de la dernière occurence
de A.
Fonctions analytiques sur la
distribution des valeurs
Les quatres dernières fonctions
permettent d'avoir des informations quant à la distribution des
données. Les fonctions PERCENTILE_CONT et PERCENTILE_DISC permettent
d'obtenir le percentile d'une distribution de données tandis que les
fonctions CUME_DIST et PERCENT_RANK permettent de déterminer le rang
de la donnée relativement à la distribution.
PERCENTILE_CONT et PERCENTILE_DISC
Les fonctions PERCENTILE_CONT et
PERCENTILE_DISC permettent de calculer le percentile d'une
distribution basé sur un ordonnancement et une partition de données
spécifiée. La différence entre ces deux fonctions est que, pour la
première, il va traiter la distribution numérique comme étant une
distribution continu, qui peut prendre une infinité de valeur,
tandis qu'avec la fonction PERCENTILE_DISC, il traite la distribution
comme étant un ensemble de valeurs discrètes et fini. Dans le
premier cas, la valeur retournée peut ne pas exister dans la
distribution tandis que dans le deuxième cas, la valeur retournée
doit obligatoirement exister dans la distribution.
Dans le cadre de notre exemple avec les
items vendus par mois, on peut calculer le 33ième percentile de
chaque année de cette façon :
Dans le résultat, on peut affirmer
que, dans le cas d'une distribution continu, 35% des données sont
égal ou en deça de 497.75, tandis que dans une distribution
discrète, 35% des données sont égal ou en deça de 230
CUME_DIST et PERCENT_RANK
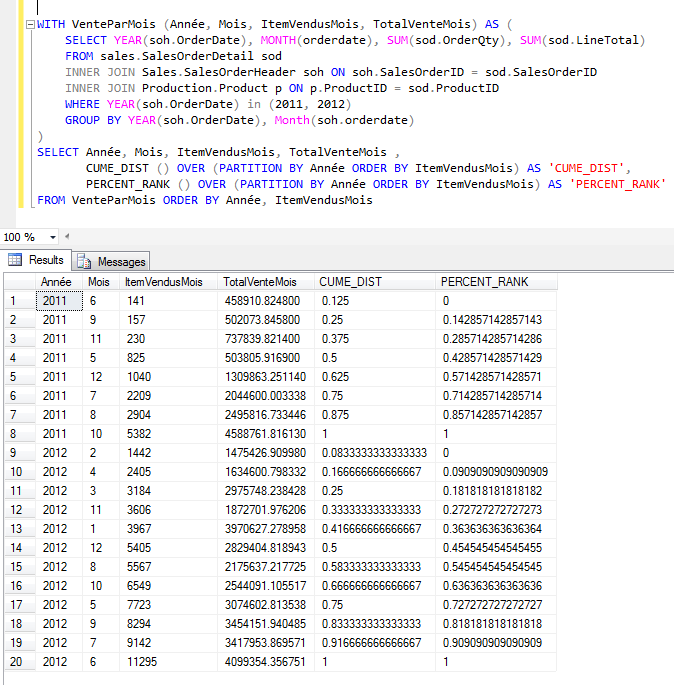
Ces deux fonctions permettent de
calculer la position relative en pourcentage de l'occurrence courante
par rapport à l'ensemble du jeu de données.
La fonction CUME_DIST (distribution
cumulative) permet d'obtenir la position relative par rapport au jeu
de données où la valeur retournée indique le pourcentage de valeur
qui est égale ou inférieur à la valeur courante. De façon plus
concrète, la valeur retournée est égale à r/n où r la position
de l'occurrence courante et n est le nombre total du jeu de donnée.
La fonction PERCENT_RANK permet aussi
de calculer le rang relative de l'occurrence courante par rapport au
jeu de donnée, mais la première ligne aura toujours la valeur zéro.
On peut voir les différences entre ces
deux fonctions dans le résultat suivant :
Références: